查找华为OSPF配置命令,发现以下几条加速OSPF收敛的方法:
1、设置OSPF LSA接收的时间间隔和LSA更新时间间隔。对于网络稳定对路由收 敛时间要求高的环境,可为0。对于网络或路由频繁震荡的环境,设为0会 过多占据带宽和交换机资源。
2、Hellointerval越小虽然更快发现网络拓扑发生变化,但网络开销资源也会 越大,默认nbma-30s,广播-10秒
3、Dead 默认nbma 120秒 广播40秒
4、设置OSPF路由计算时间间隔。
详细探究几种情况下对OSPF收敛时间的影响:
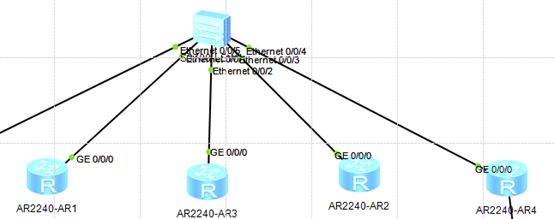
配置:4台路由器连接一台交换机,二层可通。均配置loopback 地址,分别是1.1.1.1,2.2.2.2,3.3.3.3,4.4.4.4。配置OSPF,所有接口都在area 1。其中r2和r3分别是DR和BDR。
情景一:R1 g0/0/0 口shutdown。
分析OSPF重新收敛的过程:
经过holdtime(dead)(华为默认广播网络为40秒)40秒后,r2和r3与r1邻接关系转为down。因为是同一网段,LSDB重新更新到一致的手段是“重头再来”:r3通告自身router lsa,network lsa到224.0.0.5,r2,r4确认。R2通告router lsa到224.0.0.5,r1,r4确认。R4是Dother,通告自身router lsa到224.0.0.6,r1通告该lsa到224.0.0.5,然后r2才确认,LSDB一致,然后根据spf算法立刻更新路由。此时你会发现同一网段的所有LSA实例都更新到最新,但是r1的1.1.1.1因为老化时间没到,依然存在,但是路由表中相应条目已经没有。
结论:此时可以通过设置dead时间加速收敛。
情景二:启动R1。此时经历了较长的时间才互相收到hello(猜测原因是先前刚shutdown掉R1,lsdb中仍然保留其router id,正常的情况是hello interval 默认时间10秒之内就可以互相收到hello。)
分析OSPF重新收敛的过程:
简单说r1和r4 2-way,和r2和r3 full。然后整个网段“重头再来”,发现此时LSDB中的老化时间又变0,
情景三:同一网段增加一台路由器R6

分析OSPF重新收敛的过程:
Hello interval默认10秒间隔内,互相收到hello。接下来过程同上,整个网段所有路由器的接口重新再通告一遍自身的LSA。
情景四:不同网段45.1.1.0增加一台路由器r5

分析OSPF重新收敛的过程:
Hello interval默认10秒间隔内,互相收到hello。跟同一网段的区别是,只是r4通告ls update更新,包括一个网络lsa,一个路由lsa。10.10.10.0网段的LSA的老化时间不会清0.
结论:可以设置hellointerval的时间加快路由收敛。
相比于rip,ospf的收敛速度只是一般来说快于rip。
在某些情况,比如rip设置更新包文的时间间隔,设置老化时间和刷新时间,以及设置触发更新都可以加快rip收敛。因此ospf收敛速度一定快于rip,这是不严谨的说法。
快速收敛
网络收敛的过程,如同在平静的湖面丢下一粒石子,泛起一圈圈涟漪,等涟漪传导到湖面的边缘部分,湖面就静止了,网络的术语称之为网络收敛。
Hello作用是为了发现邻居,并周期性地发送和接收,为了发现邻居在或不在。如果不在,将启动超时机制,即连续4个hello时间周期内,没有收到邻居的hello,则宣布和邻居直连的链路失效,然后将这种link down 的消息扩散出去。hello缺省时间为10秒,detect time = 4 *hello,所以发现失效时间(detect time)为40秒,加上LSA update 的扩散时间,加上运算SPF算法的延迟时间,再加上SPF本身的运算时间(时间小,基本可以忽略),这整体的时间应该为:
Detect time + Flooding time + SPF Delay time + SPF time = 40 + (<1) + (<=6) + (<1)= 48秒
这整体的时间就是收敛时间,大家可以看到其中detect time占了超过了80%的份额;
如果我们调整hello time=5秒,则收敛时间= 28 秒;
调整hello time= 1秒,则收敛时间=12秒。这个hello时间在cisco平台上是最小值,通过调整hello时间来减少收敛时间到了极限值。那个flooding time 和SPF time 我们无法控制,那只有操作那个SPF delay time了,如果可以将其控制在1-2秒之内,则收敛时间将降为<8秒,这是通过修改OSPF参数能达到的极限值。


文章评论